Über die Eignung von (zensierten) LLM um korrekte und nützliche Antworten auf generische Fragen zu erhalten, gibt es einige Erfahrungen und Tests, u.a. auch Zweifel besonders an der Zensur und Privacy bei kommerziellen Modellen.
Wo LLM aber ohne Zweifel ein massives neues Tool darstellen, ist die Analyse und Strukturierung von Dokumenten, insbesondere Spreadsheet/Datenbank Bereich oder auch um Code/Programmierlösungen für überschaubare Problemstellungen zu liefern. Auch in diesen Bereichen ist das Wissen und die Erfahrung des Prompters entscheidend für das Resultat (nach mehreren Prompts).
Dokumentanalyse (PDF, PDT, DOCX, usw.)
Ein Grundlimit ist die Anzahl der verarbeitbaren Tokens mit ungefährer Umrechnung in Zeichen und Wörtern, akzeptieren von Dokumentformaten, sowie Umgang den Sprachen Englisch, Deutsch und Italienisch einzeln und auch gemischt. Und auch das Datum des letzten Trainings. Hier die Ausgabe von Claude 2.1 am 23.11.2023 (Edits von mir in Kursiv, nicht durchgängig auf Korrektheit gecheckt):
| Modell | Version | Max. Eingabe-Tokens | Akzeptierte Formate | Sprachen | Sortierte Listen | DOCX/ODT Output | HTML-Output | Stand |
|---|---|---|---|---|---|---|---|---|
| Claude | 2.1 | 200.000 | Text, PDF, CSV, JSON | Englisch, etwas Deutsch und Französisch | Ja | Nein | Nein | November 2023 |
| ChatGPT | 4 | 2.048 (128k?) | Text | Englisch, etwas Deutsch, Französisch, Spanisch | Ja | Nein | Nein | Dezember 2022 |
| ChatGPT | 3.5 Turbo | 4.096 | Text | Englisch, etwas Deutsch, Französisch, Spanisch | Ja | Nein | Nein | Mai 2022 |
| Bard | 1 | 1.024 | Text | Englisch, etwas Deutsch, Französisch, Spanisch | Ja | Nein | Nein | Februar 2023 |
| GPT-3 | Davinci | 2.048 | Text | Englisch | Ja | Nein | Ja, basics | 2020 |
| Jurassic-1 | J1-Jumbo | 2.048 | Text | Englisch | Ja | Nein | Ja, basics | März 2022 |
| PaLM | 540B | 8.192 | Text | Englisch, etwas Deutsch, Französisch | Ja | Nein | Ja, basics | April 2022 |
Einige starke Limits sind bereits ersichtlich. Noch stärker werden Limits beim Finden von Fakten in einem Dokument ersichtlich. Greg Kamradt hat dies am 21.11.2023 analysiert: Claude 2.1 (200K Tokens) – Pressure Testing Long Context Recall (X/Twitter). Sich auch X/Twitter und YouTube Channel.
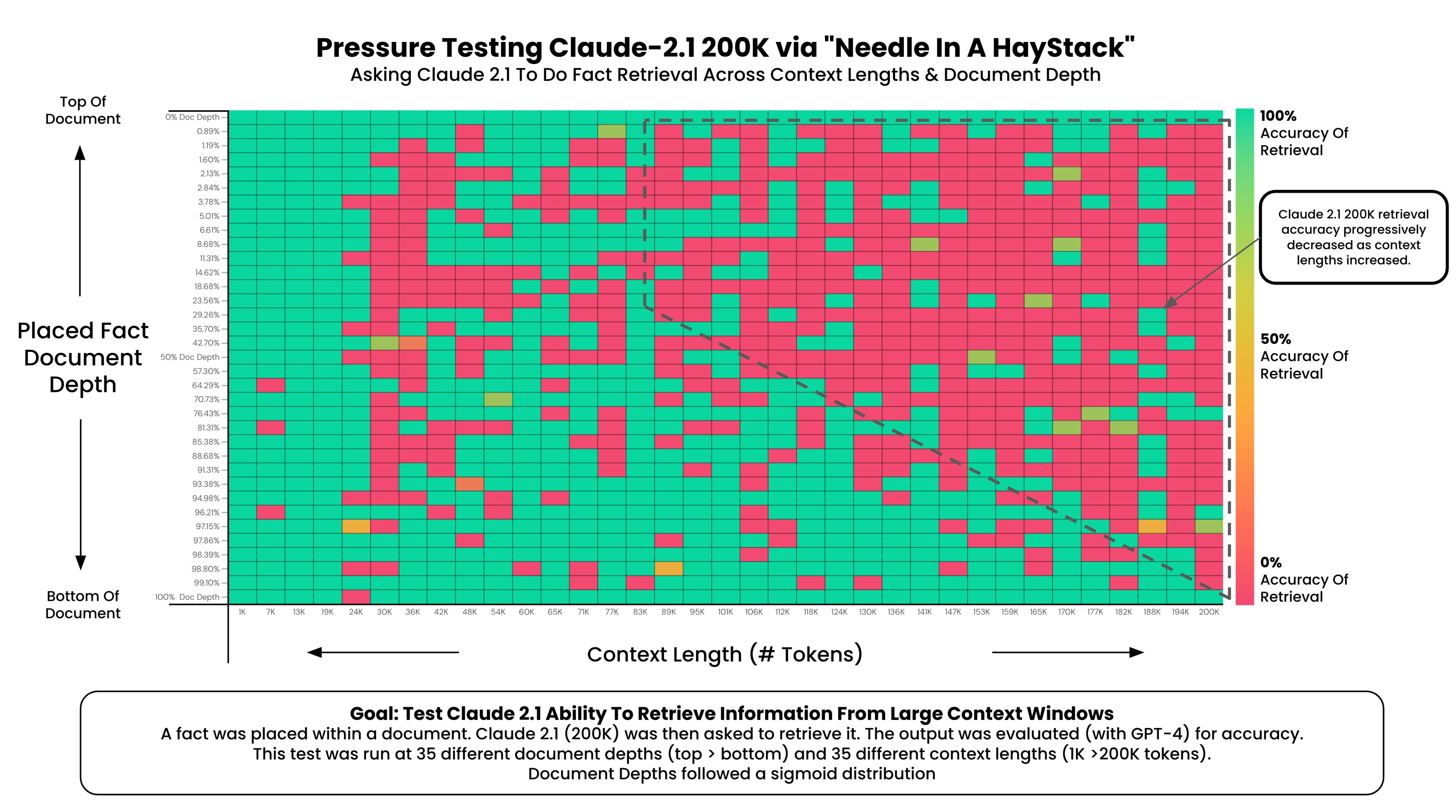
Bereits bei kleinem Input bis 19K werden Fakten nicht fehlerfrei gefunden, bis 89K ist eine ziemlich große Nichtauffindung feststellbar. Bis 200K steigt diese weiter vom ersten Drittel des Dokuments bis hin zu fast dem ganzen Dokument. Dies muss einem bei Nutzung bewusst sein.
Pressure Testing GPT-4-128K With Long Context Recall

OpenAI/ChatGPT models gibt ein paar weitere Einblicke, wie oben dargestellt ist gpt-4-1106-preview ist GPT-4 Turbo bis 64K zuverlässig bei Faktenfindung, kostet allerdings im Nov. 2023 $20/Monat.
Somit ist das derzeit frei zugänglichen kommerziellen Modell Claude 2.1 200K wohl nicht für zuverlässige Dokumentenanalyse nutzbar. ChatGPT 3.5 Turbo 4K ist aufgrund des geringen Token-Inputs nicht sehr attraktiv und Analysen zu anderen Modellen wurden nicht gefunden/recherchiert.
Update Feb. 2024: LLama-2 7B: 400K context length – Beyond Limits? diskutiert die Studie Soaring from 4K to 400K: Extending LLM’s Context with Activation Beacon und im verlinkten YT-Zeitpunkt wird auch die Zuverlässigkeit laut Fig. 4 betrachtet, welche hoch bleibt. Vermutlich also ein interessanter Ansatz.
Google Gemini Pro 1.5: Jeff Dean der Chef-Forscher DeepMind teilt auf X/Twitter Infos zu diesem noch unveröffentlichten mixture-of-expert (MoE) Architektur, welches scheinbar 128K Tokens/Kontext für alle und bis zu 1 Million für Abo-Kunden bieten soll. Laut den geteilten Grafiken sollen Nadeln im Heustock noch bei 7 Mill. Wörtern (10 Mill. Token) mit annehmbarer Genauigkeit gefunden werden.

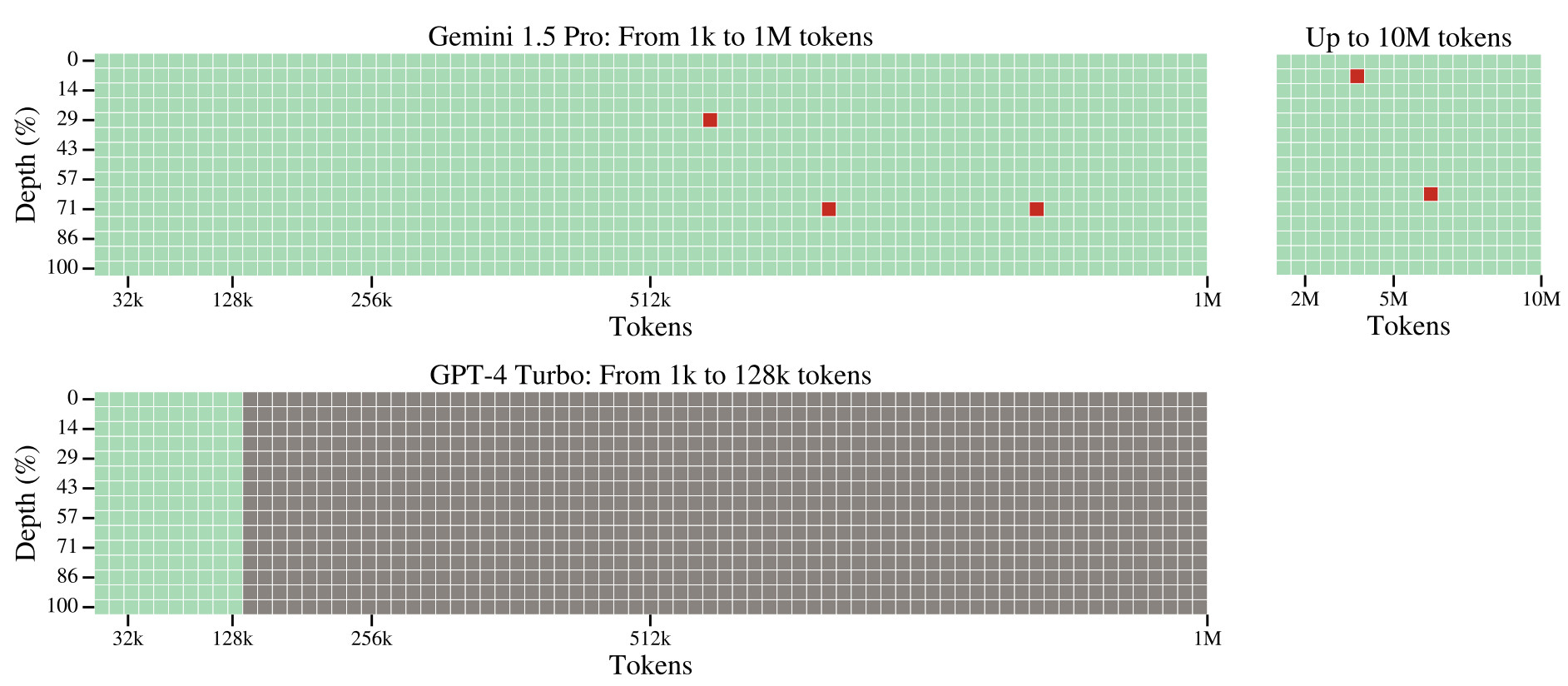
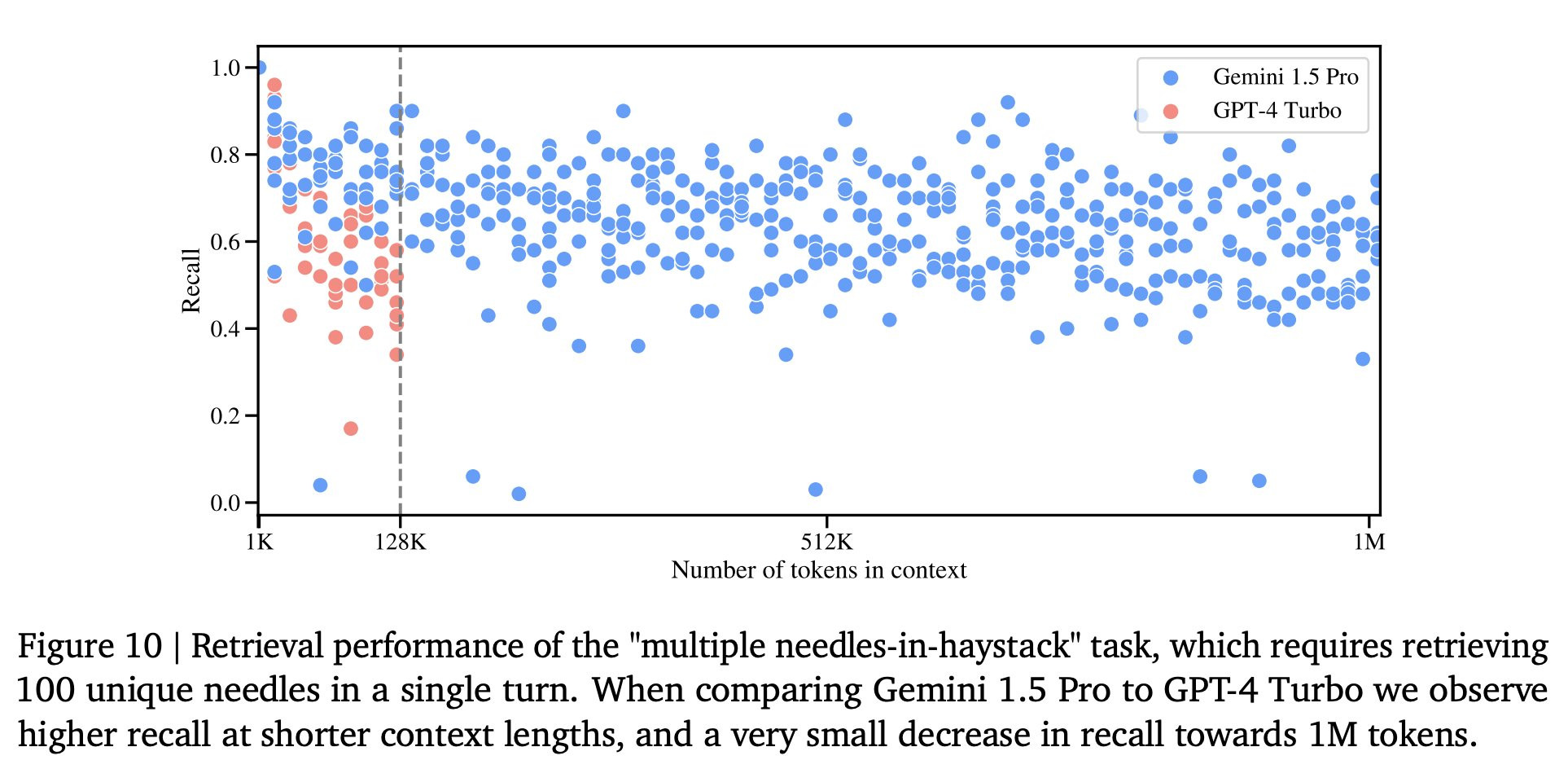
Dieser Test scheint die Genauigkeit darzustellen, mit der z.B. unterschiedliche Namen oder Orte mit einer Abfrage extrahiert werden können.
Gemini 1.5 Pro soll bei großen Coding-Projekten innerhalb des Token-Limits in der Lage sein spezifische Funktionen zu finden und diese auch zu manipulieren: Navigating large and unfamiliar code bases; Analyzing and understanding complex code bases;
Weiters gegeben sein soll die Fähigkeit lange Videos akkurat zu analysieren; Analyse und logische Konklusionen von langen Textdokumenten;